
Machine learning (ML) has become a hot topic in the last few years, but what you may not realize is that the concept of machine learning has been around for decades. The design of machine-learning systems used to this day is based on the human brain model described by Donald Hebb in 1949 in his book “The Organization of Behavior.”
Hebb noted that when cells in the brain fire in a repeated pattern, synaptic knobs are formed or enlarge if they already exist. The same principle is applied to nodes in a digital neural network. Nodes develop relationships that grow stronger if they are activated simultaneously and weaken if they fire separately. Reinforcement learning is one form of machine learning based on this concept, but let’s not get ahead of ourselves.

“Machine Learning is the study of computer algorithms that improve automatically through experience.” — Tom Mitchell
IBM programmer and AI pioneer Arthur Samuel coined the term “machine learning” in 1952. Samuel had written a checkers-playing program that “learned” and got better the more it played. He used a technique called “alpha-beta pruning,” which would score the board based on the position of the pieces and either side’s chances of winning. This model evolved into the Minimax algorithm that is still taught today.
Throughout the decades, other pioneers combined, adapted and applied the Hebb and Samuel models (and those to follow) to various applications. For example, in 1957, Frank Rosenblatt built the Mark 1 perceptron, one of the very first image recognition machines and the first successful neuro-computer.
Many applications like speech and facial recognition, data analytics, natural language processing, and even the phishing alerts in our email are based on the work of these innovators.
A decade later, in 1967, Marcello Pelillo developed the “nearest neighbor rule” for pattern recognition. The nearest neighbor algorithm is the grandfather of today’s GPS mapping applications. Others continued to build on these foundations creating multi-layered perceptron neural networks in the 1960s and backpropagation in the 1970s, which researchers use to train deep neural networks.
All of this prior work formed the cornerstones of the research going on today. Many applications like speech and facial recognition, data analytics, natural language processing (speech synthesis), and even the phishing alerts in our email are based on the work of these innovators. Today’s automation in nearly every sector of the economy has shoved machine learning to the forefront, but it has always been working in the background.
What Is Machine Learning?
Academia has not settled on one standard definition for Machine Learning. The scope of ML is broad and not easily boiled down to one sentence, although some have tried…
MIT’s definition reads, “Machine-learning algorithms use statistics to find patterns in massive amounts of data, [including] numbers, words, images, clicks, what have you. If it can be digitally stored, it can be fed into a machine-learning algorithm.”
“Machine learning is the science of getting computers to act without being explicitly programmed,” is how Stanford’s Machine Learning course describes it.
Meanwhile, Carnegie Mellon says, “The field of Machine Learning seeks to answer the question, ‘How can we build computer systems that automatically improve with experience, and what are the fundamental laws that govern all learning processes?'”
For practical purposes, we can toss those ingredients into our pot and boil it down to this:
Machine learning involves training a computer with a massive number of examples to autonomously make logical decisions based on a limited amount of data as input and to improve that process with use.
Not All “Thinking” Computers Are Created Equal
We hear many other terms tossed around in discussions on machine learning, particularly artificial intelligence and deep learning. While these fields are related, they are not the same. Understanding the relationship between these technologies is key to learning what machine learning is exactly.
Artificial intelligence, machine learning, and deep learning are three computer science categories that nest inside one another. That is to say, machine learning is a subset of AI, and deep learning is a subset of ML (see diagram).
General artificial intelligence is a set of instructions that tell a computer how to act or display human-like behavior. The way it reacts to input is hardcoded, ie, “If this happens, do that.” The general rule of thumb is if the AI is explicitly told what decisions to make, the program lies outside the realm of machine learning.

Machine learning is a subset of AI that can act autonomously. Unlike general AI, an ML algorithm does not have to be told how to interpret information. The simplest artificial neural networks (ANN) consist of a single layer of machine learning algorithms (see below).
Like a child, it needs to be trained using tagged or classified datasets or input. In other words, as data is introduced, it has to be told what it is, i.e., this is a cat, and this is a dog. Armed with that information, the ANN can then complete its task without explicit instructions to get to the results or output.

Deep learning is a subset of AI and machine learning. These constructs consist of multiple layers of ML algorithms. Thus, they are often referred to as “deep neural networks” (DNN). Input is passed through the layers, with each adding qualifiers or tags. So deep learning does not require pre-classified data to make interpretations.
We’ll explore the differences between ML and DL more in a moment.
How Do Neural Networks Learn?
Whether we are referring to single-layer machine learning or deep neural networks, they both require training. While some simple ML programs, also called learners, can be trained with relatively small quantities of sample information, most require copious amounts of data input to function accurately.
Regardless of the initial needs of the ML system being trained, the more examples it’s fed, the better it performs. Deep learners generally need more input than single-layer ML since they have nothing telling them how to classify the data. It is not uncommon for systems to use datasets containing millions or hundreds of millions of examples for training.
How ML programs use this massive volume of data depends on which type of learning is employed. Currently, there are three learning models—supervised, unsupervised, and reinforcement. Which to use depends mainly on what needs to be accomplished.
Supervised Learning
Supervised learning is not what its name implies. Operators don’t sit around watching the learner as it works and adjusting it for errors. Supervised learning just means the input data must be labeled or categorized for the algorithms to do their jobs. The system has to know what the input data is to figure out what to do with it.

Supervised learning is the most common ML training method, and is used in numerous familiar applications.
For example, many services such as the PlayStation Network, Netflix, Spotify, and others use it to generate curated lists based on user preferences automatically. Each time a user buys a game, watches a movie, or plays a song, the ML algorithms record and analyze that data and its tags, then search for similar content. The more the service is used, the better the system learns and predicts what the user would like.
Unsupervised Learning
Unsupervised learning requires no labels. In this case, the learner looks for patterns and creates its own categories. For example, if fed an image of a dog, it cannot classify it as such because there is no data to tell it that is what it is. Instead, it looks at things like shapes or colors and creates a rudimentary classification. As it is fed more data, it can refine its profile of dogs, creating additional tags that distinguish them from other objects or animals.
Single-layer ML systems are not efficient at working with unlabeled input. Part of this is because it requires deep neural networks to make sense of the information. Multilayer networks are more suited for this type of data handling as each layer performs a specific function with the input before passing it to another layer along with its results. Since ANNs are vastly more common than DNNs, unsupervised learning is considered a rare form of training.
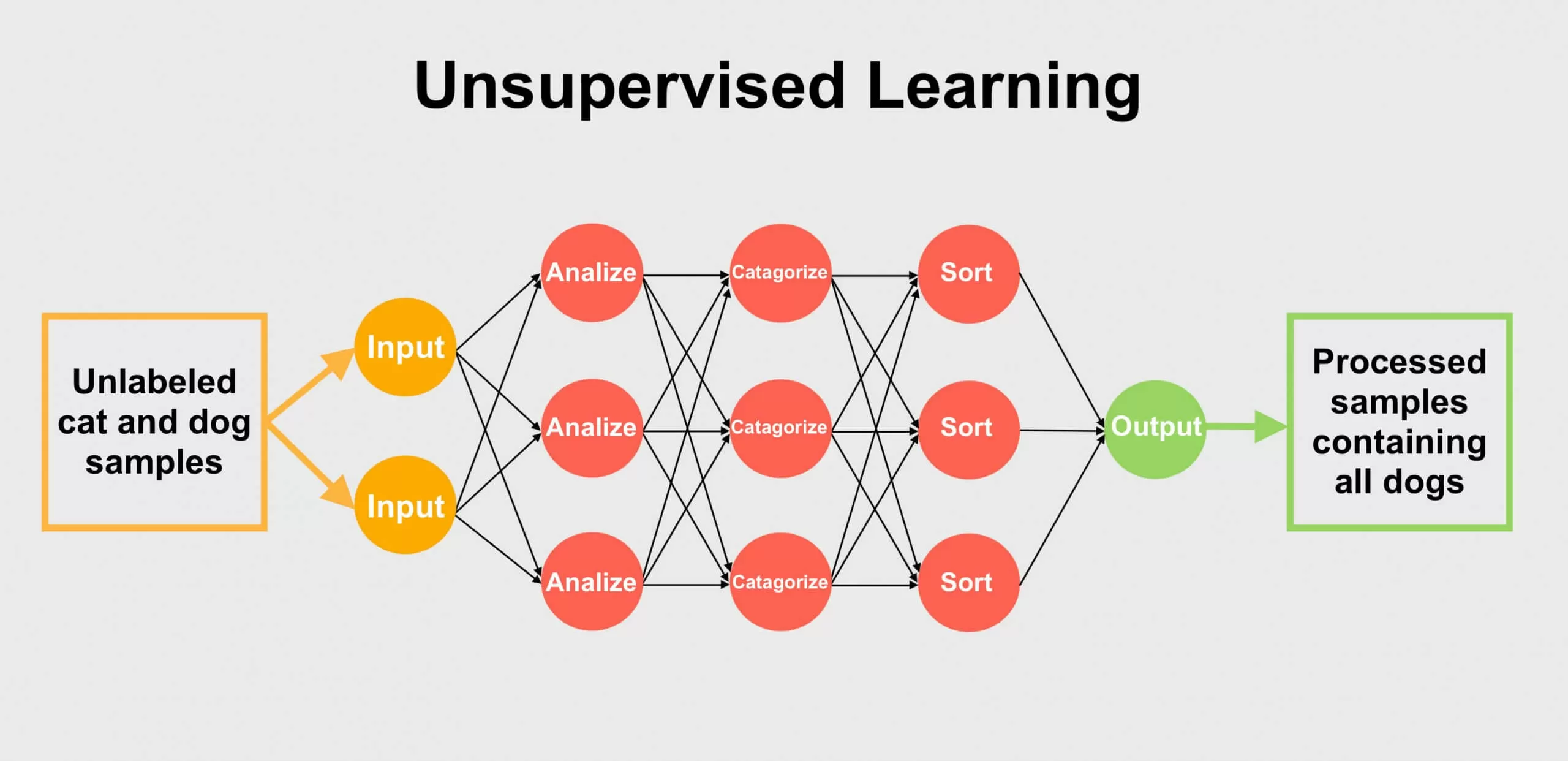
However, there are well-known examples of ML systems that use unsupervised learning. Google Lens uses this learning method to identify objects from static and live images. Another example would be the algorithms that cybersecurity firm Darktrace uses to detect internal security leaks. Darktrace’s ML system uses unsupervised learning in a way that is not unlike the human immune system.
“It’s very much like the human body’s own immune system,” co-CEO Nicole Eagan told MIT Technology Review. “As complex as it is, it has this innate sense of what’s self and not self. And when it finds something that doesn’t belong—that’s not self—it has an extremely precise and rapid response.”
Reinforcement Learning
The third training method also deals with unlabeled data. As such, reinforcement learning is also only used in deep learners. Both unsupervised and reinforced systems handle data with specific predefined goals. How they reach these goals is where the algorithms differ.
Unlike unsupervised learners, which operate within specific parameters to lead them to the end goal, reinforcement learning uses a scoring system to direct it to the desired outcome.
The algorithms try different ways to achieve their goal and are rewarded or penalized depending on whether their approach is effective or ineffective in obtaining the final results. Reinforcement training is well suited to teaching AI how to play and win at games like Go, Chess, Dota 2, or even Pac-Man.
This system of training is analogous to playing the Hot and Cold game with a toddler. You tell the child to find the ball, and as he looks, you direct him with the reinforcement words “hotter” and “colder” based on whether he is getting closer or further from the ball—reinforcement. Using unsupervised learning, the toddler would have to find the ball by following a predefined map or directions. In either case, the child still has to figure out what a ball is.
Reinforcement learning is the newest form of training for ML systems and has seen increased research in recent years. As mentioned earlier, Arthur Samuel’s 1952 checkers game was an early form of reinforcement machine learning. Now deep learners like Google’s AlphaGo and OpenAi’s Dota 2 bot, “Five,” use reinforcement learning to beat professional human players in games much more complicated than checkers.
Machine Learning Today and Tomorrow
While machine learning has been around for decades, it’s only in recent years that we’ve seen a big push for practical applications that use the technology. Chances are you regularly use a device or application that relies on ML algorithms. Smartphones are an obvious example, as are various apps like voice assistants, maps, and exercise trackers. There are also other use cases that are less obvious but can do amazing things.
Surveillance systems are far from just simple mounted video cameras monitored by security personnel these days. Advanced systems now employ machine learning to automate various tasks, including detecting suspicious behavior and tracking individuals through facial recognition.
Working in Nevada casinos for many years, I saw first hand a surveillance system that could not only flag potential cheaters but also follow the suspect throughout the casino automatically switching to whichever camera had the person in view. It was amazing to watch the surveillance system as it tracked someone through the casino and even into the parking lot without any human intervention.
“The world is running out of computing capacity. Moore’s law is kinda running out of steam … [we need quantum computing to] create all of these rich experiences we talk about, all of this artificial intelligence.” — Satya Nadella, Microsoft CEO.
The machine learning applications that we see today are already quite astonishing, but what does the future hold? The artificial intelligence field is only just now beginning to blossom.
Machine learning and deep learning algorithms have infinite room for growth, and we’re sure to see even more practical applications entering the consumer and enterprise markets in the coming decade. In fact, Forbes notes that 82 percent of marketing leaders are already adopting machine learning to improve personalization. So, we can expect to see ML leveraged commercially in targeted advertising and personalization of services well into the future.
The next big boom is likely to be quantum machine learning. Researchers from the likes of MIT, IBM, and NASA have already been experimenting with applying quantum computing to machine learning. Unsurprisingly they have found that certain problems can be solved in a fraction of the time over contemporary processing hardware. On that same note, Microsoft and Google recently announced plans to move forward in the field of quantum ML, so it is likely we will be hearing and seeing a lot more of this in the near future.
More Explainers
Source link






